- Home
- Users & Science
- Find a beamline
- Structural biology
- How to use our beamlines
- Run Your Experiment
- EDNA Autoprocessing
EDNA Autoprocessing
EDNA fast autoprocessing information
EDNA fast processing
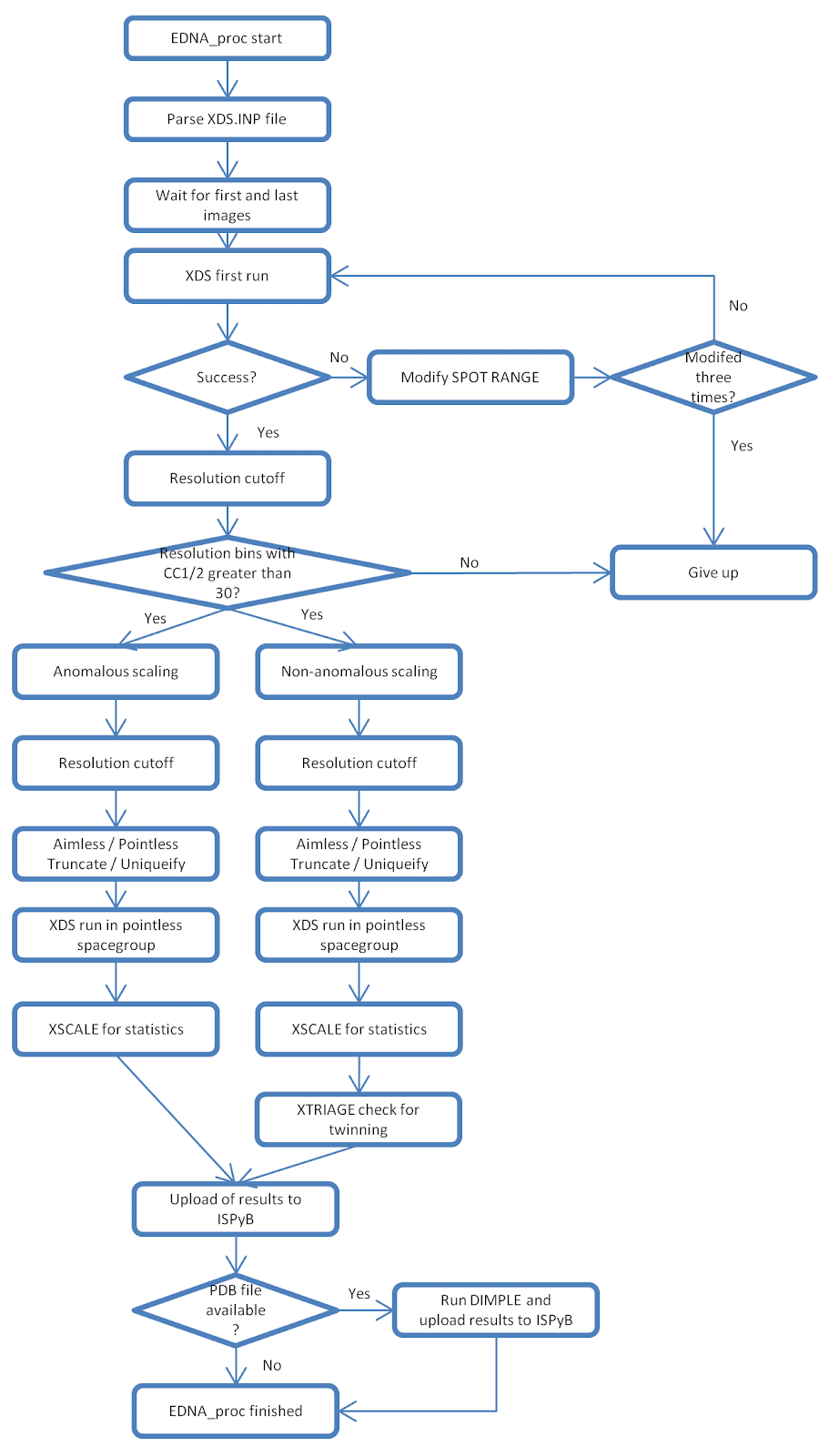
This automatic data processing pipeline is started automatically by mxCuBE when data are collected. The processing is designed to be quick and uses a sequence of XDS, XSCALE, Pointless, Aimless, Truncate and Uniquify built within the EDNA framework. As with other Automatic Processing, XSCALE is run to produced merge and unmerged data with and without anomalous ON.
Space group input
If a space group and a unit cell (you need both !) are provided in ISPyB and/or provided in the mxCuBE (below) interface the integration will use this information.

IMPORTANT: Fast processing is conceived to give the best processing output in the fastest way. Users are responsible to provide the correct space group and unit cell information. No check is performed at this stage on the supplied information. For processing in alternative space group please refer to GrenADES parallel processing
Data output
Results for fast processing can be found in ./PROCESSED_DATA/xds_prefix_run1_1/results/fast_processing
FIle naming follows the convention:
prefix_run1_merged_anom_XSCALE.lp
XSCALE log
prefix_run1_aimless_anom.log
Aimless log after XSCALE with anom
prefix_run1_aimless_anom.mtz
mtz output from Aimless, contains IMEAN, I+, I-
prefix_run1_aimless_noanom.mtz
mtz output from Aimless, contains IMEAN
prefix_run1_merged_noanom_XSCALE.lp
XSCALE log with merge and noanom
prefix_run1_aimless_noanom.log
Aimless log after XSCALE with anom
prefix_run1_successful_XDS.INP
XDS.INP edited during processing
prefix_run1_anom_truncate.mtz
mtz generated by truncate with anom
prefix_run1_truncate_anom.log
Truncate log
prefix_run1_noanom_truncate.mtz
mtz generated by truncate with noanom
prefix_run1_truncate_noanom.log
Truncate log
prefix_run1_unmerged_anom_pointless_multirecord.mtz
multi batch unmerged mtz from pointless after XSCALE with no anom
prefix_run1_unmerged_anom_XSCALE.lp
XSCALE log
prefix_run1_unmerged_noanom_pointless_multirecord.mtz
multi batch unmerged mtz from pointless after XSCALE with anom
prefix_run1_unmerged_noanom_XSCALE.lp
XSCALE log
prefix_run1_input_XDS.INP
original XDS.INP
Data download from ISPYB
All data processing statistics, resulting mtz files and some log files are available through the ISPYB interface.
Select the individual data collections and you will see an Autoprocessing tab. Within this tab there is a pull down menu and you can select if you want to see the edna_autoprocessing or the different parallelprocs. Once selected the associated log files and mtz files are visible and can be selected for download. It is also possible to download all files as a tar file.
For the EDNA processing there is also a status history - so in the case of failure of the autoprocessing - it is clear at which point the auto processing stopped.
The input XDS file used for the initial integration is also available through this interface.
partners



European Synchrotron Radiation Facility - 71, avenue des Martyrs, CS 40220, 38043 Grenoble Cedex 9, France.